[MSSQL] 인덱스(클러스터드, 논 클러스터드)
docs.microsoft.com/ko-kr/sql/relational-databases/indexes/indexes?view=sql-server-ver15
인덱스 | Microsoft 문서 - SQL Server
인덱스
docs.microsoft.com
qiita.com/kz_morita/items/41291516ff3ee2650554
SQLServerのインデックスについてざっくりとまとめてみた - Qiita
SQLServerについて SQLServerのインデックスについて学ばせていただく機会があり、ものすごく勉強になったのでまとめます。 はじめに 他のDBと同様にSQLServerにもインデックスの概念は存在しま
qiita.com
#인덱스란
검색 속도를 향상시키기 위한 기능
인덱스가 없는 테이블의 경우 어떤 데이터를 찾든 테이블의 처음부터 끝까지 탐색한다
예를 들면, 책의 앞장에 있는 목차와 같은 개념이다
챕터1 10페이지~
챕터2 50페이지~
챕터3 100페이지~
책의 내용을 파악하고 찾으려는 내용이 어디있는지 기록해두는 것
즉, 자주 액세스(WHERE, JOIN ON등 조건문)가 일어나는 컬럼을 인덱스로 만들어 놓는 것이 좋다
#인덱스의 구조
인덱스는 B-Tree구조를 사용한다
루트 노드(최상위) > 내부 노드(중간) > 리프 노드(최하위)
#인덱스로 설정해야할 컬럼의 조건
데이터의 중복이 낮다
선택도가 낮다(해당컬럼에서 특정값을 골라낼 확률, 주민등록번호같은 중복없이 고유값을 지닌 컬럼이 선택도가 낮음)
활용도가 높다(WHERE같은 조건문에서 자주 쓰이는 컬럼)
#MSSQL의 인덱스종류는 아래가 있다
힙표(힙 : 넣은 순서대로 들어감 )
클러스터드 인덱스(Clustered Index)
논 클러스터드 인덱스(NonClustered Index)
복합 인덱스
부가열 인덱스
우선 인덱스를 공부하기전 쿼리의 종류에 대해 알아보자
#쿼리
포인트쿼리 : 검색 결과가 1행인 것
SELECT * FROM TABLE WHERE BoardNum = 1; --기본키같이 테이블에서 하나만 존재범위 쿼리 : 검색 결과가 여러행인 것
SELECT * FROM TABLE WHERE BoardNum BETWEEN 1 AND 10 ; -- 1부터 10까지 여러행커버드 쿼리 : 검색 결과가 정해져 있는 것(가장 속도가 빠름)
SELECT InsertDate FROM TABLE WHERE BoardNum = 1; -- 검색값이 정해져있음
#인덱스의 종류
#힙 테이블(인덱스가 없는 테이블)
삽입된 순서대로 데이터가 정렬되어있음
데이터를 찾을때는 처음부터 끝까지 순차적으로 찾아감
#클러스터드 인덱스(Clustered Index) 특징
테이블의 레코드가 정렬되어 있음, 그렇기에 하나의 테이블당 1개만 생성 가능
(정렬된 상태에서 중복값이 생기면 DB에 문제가 생기기 때문 1,1,2,2,3,3.. 이런 식으로)
테이블 기본키(Primary Key)를 설정하면 자동으로 생성 됨
데이터 입력, 수정, 삭제 후에도 기본키를 기준으로 항상 정렬상태 유지
(변경이 있을때 매번 정렬하기 때문에 비용이증가하므로 자주 갱신,변경이 일어나는 테이블은 사용하지 않는 것이 좋다)
범위쿼리에서 성능을 발휘(정렬 되어 있기 때문에 순차 액세스 속도가 빠름)
클러스터드 인덱스의 리프노드에는 레코드의 값(데이터)가 존재함

USE 서버명;
GO
-- 테이블 생성
CREATE TABLE dbo.TestTable
(TestCol1 int NOT NULL,
TestCol2 nchar(10) NULL,
TestCol3 nvarchar(50) NULL);
GO
-- 클러스터 인덱스 작성
CREATE CLUSTERED INDEX 인덱스명 ON 테이블명 (컬럼명 ASC/DESC);
GO또한 아래와 같이 테이블 생성시 기본키를 설정하면 클러스터드 인덱스는 기본키를 기준으로 자동으로 생성된다
CREATE TABLE dbo.TestTable
(TestCol1 int Primary Key,
TestCol2 nchar(10) NULL,
TestCol3 nvarchar(50) NULL);
#논 클러스터드 인덱스(NonClustered Index) 특징
정렬되어 있지않음, 그렇게 때문에 여러개 생성 가능(250개 미만)
데이터 입력, 수정, 삭제 후에 자동 정렬이 되지 않음(그래서 자주 갱신하면 성능이 떨어짐)
포인트쿼리에서 성능을 발휘(키(주소)로 값을 찾는 구조이기 때문)
테이블 제약조건 고유키(unique) 설정하면 자동 생성 됨
인덱스의 리프노드에는 실제 데이터를 참조하는 키(주소,GID(레코드ID))가 존재하며
키(주소,GID(레코드ID))를 이용하여 데이터페이지에 액세스 하여 값을 얻는다
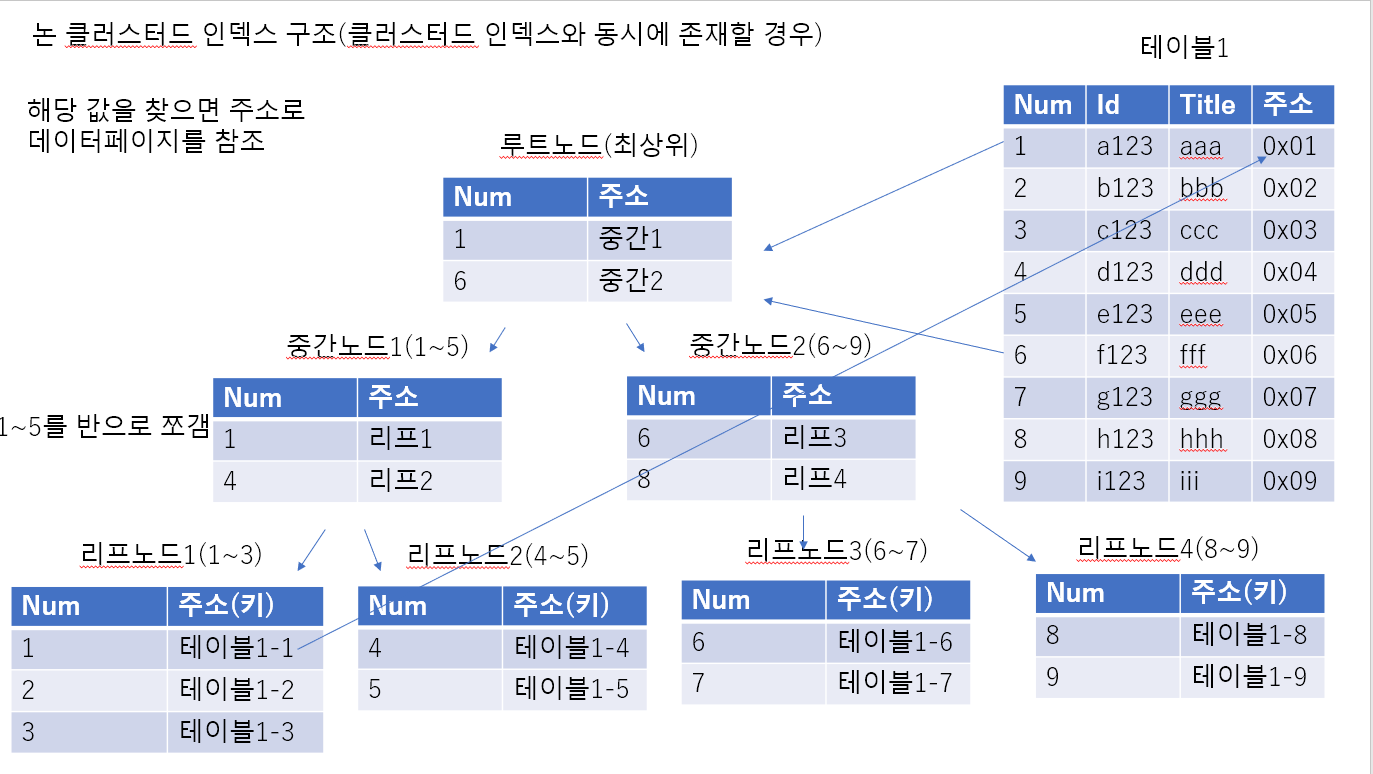
#테이블에 클러스터드 인덱스와 논클러스터드 인덱스가 동시에 존재하는경우
그림처럼 리프노드에는 키값이 존재하고
(클러스터드 인덱스가 존재하면 테이블이 정렬되어 있기 때문에)
테이블에 논 클러스터드 인덱스만 존재할경우
리프노드에는 GID(레코드 아이디)가 존재하며 GID를 이용해 데이터페이지에서 값을 찾는다
(논 클러스터드 인덱스만 존재하면 테이블을 정렬되지 않는다)

-- 논 클러스터 인덱스 작성
CREATE NONCLUSTERED INDEX 인덱스명 ON 테이블명 (컬럼명 ASC/DESC);#데이터 페이지란?
plone93.tistory.com/107?category=919897
[자료구조] 데이터 페이지(Data Page)
#데이터 페이지(Data Page)란 데이터가 입력되면 저장되는 장소이다 흔히 insert로 데이터가 입력되면 테이블에 들어간다고 알겠지만 사실은 데이터페이지에 저장된다 테이블은 데이터페이지의 집
plone93.tistory.com
우리가 데이터를 DB에 입력하면 데이터는 테이블에 입력되는게 아닌 데이터페이지에 입력이된다
테이블은 데이터페이지의 집합체이다
#그 외
클러스터드형 인덱스가 존재하면 더이상 클러스터드 인덱스를 생성할 수 없다(하나의 테이블당 최대 1개)

클러스터드 인덱스가 없다면 생성이 가능하다

기본키를 설정하면 클러스터드 인덱스가 자동생성되고
고유키를 설정하면 논 클러스터드 인덱스가 자동생성된다

#복합 인덱스
일반적인 인덱스는 각 노드에 하나의 인덱스키가 있는데
"여러컬럼을 인덱스키로 지정"하면 복합 인덱스가 된다(boardNum, boardId와 같이 2개 이상)
복합 인덱스도 논 클러스터드 인덱스처럼 리프노드에 키(주소,GID(레코드ID))가 존재하며
키(주소,GID(레코드ID))로 테이블에 액세스 하여 값을 얻는다
#부가열 인덱스
복합 인덱스처럼 각 노드에 여러 인덱스키가 존재하는데
이런 구조는 사이즈가 커지기 때문에
부가열 인덱스는 리프노드에만 인덱스키가 존재한다
#인덱스가 생성된 테이블은 인덱스를 참조하며, 인덱스가 없는 테이블은 테이블을 참조한다
